Future Work
The current Nimbus implementation provides a focused solution for deploying specific types of NLP models to AWS serverless infrastructure. Based on this existing foundation, several technical directions could be explored to extend its functionality and address potential limitations.
Expanded Model Compatibility

To expand Nimbus's utility beyond its current spaCy focus, future work could include support for a wider variety of popular NLP and ML models. This would involve enhancing Nimbus to handle different libraries, runtimes, and serialization formats. Key areas for expanded compatibility include:
- Hugging Face
transformers: Supporting deployment of readily available pre-trained or fine-tuned models, especially focusing on efficient and task-specific architectures suitable for serverless deployment. - Scikit-learn Models: Enabling users to deploy models built with Scikit-learn, commonly used for efficient text classification, clustering, and feature extraction.
- Custom TensorFlow Models: Allowing deployment of user-trained NLP models developed using TensorFlow (typically saved in SavedModel
.pbformat). - Custom PyTorch Models: Providing support for deploying user-trained NLP models developed using PyTorch (usually saved as
.ptfiles). - ONNX Models: Accommodating models converted to the Open Neural Network Exchange (
.onnx) format, which can offer performance benefits and framework interoperability. - Generic Serialized Objects (
.pkl): Supporting models or pipelines saved using Python's pickle format, common for Scikit-learn but also potentially used for other custom Python objects (while acknowledging standard security/compatibility considerations).
Supporting these diverse model types would necessitate implementing flexible runtime environments within Nimbus (e.g., via adaptable Docker images and build strategies) capable of handling varied dependencies and loading multiple model formats.
Cloud-Agnostic Deployment
Currently, Nimbus deploys exclusively on Amazon Web Services (AWS). One change we would like to make in the future is to remove the vendor lock-in and enable users to deploy their AI models and expose endpoints across a wider range of cloud providers.
Achieving this would require a reworking of the current infrastructure layer, which utilizes AWS CDK (Cloud Development Kit) . To support multi-cloud deployments, we would likely adopt a more flexible Infrastructure-as-Code (IaC) solution such as Terraform, which is widely regarded as an industry standard for provisioning cloud services.
This improvement would open up Nimbus to additional cloud environments such as Google Cloud Platform (GCP), Microsoft Azure, or even on-premises infrastructure, while reducing the long-term risks associated with changes or limitations introduced by any single cloud provider.
Function-Specific Endpoints
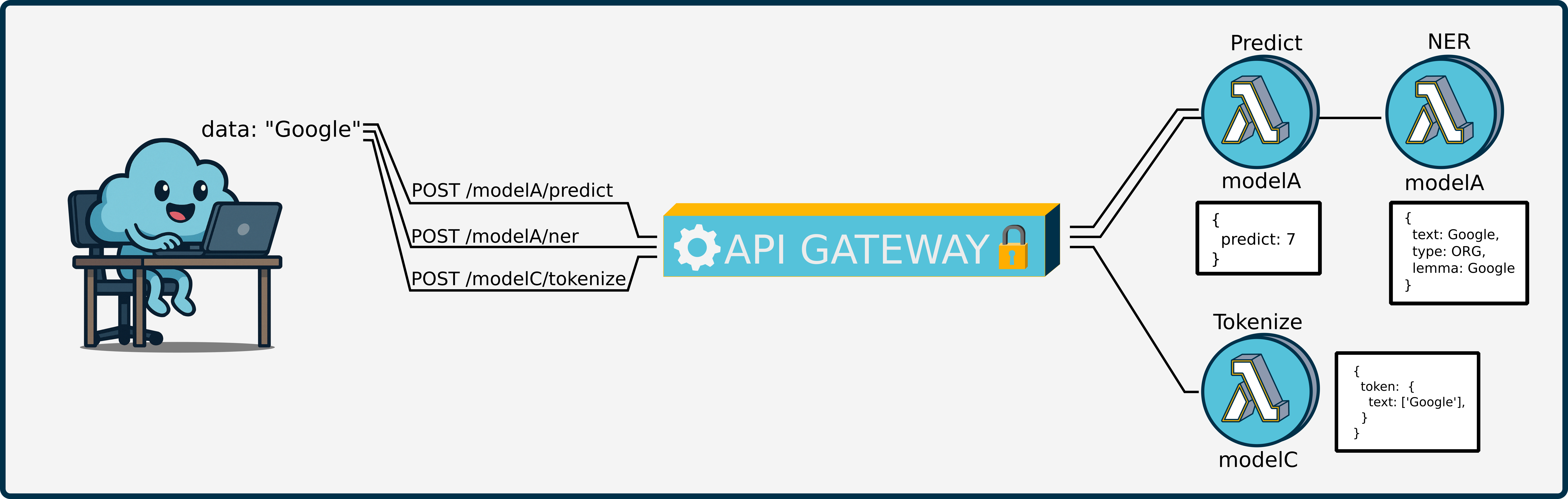
Expanding Nimbus to support multiple, function-specific endpoints in a single deployment would empower users to expose discrete model operations, rather than the monolithic /predict route. For example, one might deploy distinct paths such as /ner for named‑entity recognition or /tokenize for preprocessing, allowing users to invoke only the pipeline component they need. By scoping each endpoint to a specific Lambda handler, one can minimize HTTP payloads and latency, since requests and responses carry only the relevant data.
From an implementation standpoint, this will require:
- CDK Enhancements: Register additional HTTP routes and integrate them with their corresponding Lambda functions.
- CLI Extensions: Provide commands for users to define and annotate custom endpoints in their local state file.
- Handler Refactoring: Modularize pipeline components into standalone functions that can be invoked independently.
Together, these changes would give teams finer‑grained control over their deployed models, improve performance for high‑throughput use cases, and pave the way for richer model‑service architectures in Nimbus.