Deployment: The Bridge to Value
Having established the value these models can provide, it’s equally important to recognize that they must be deployed or put into production in order to realize that value. There are various ways to deploy a model, but a common method involves wrapping it in a service that exposes one or more endpoints that can receive input (e.g., text) and return the model’s predictions. This approach allows the model’s functionality to be integrated seamlessly into various applications, including customer-facing web frontends, internal analytics software, and automated data processing pipelines.
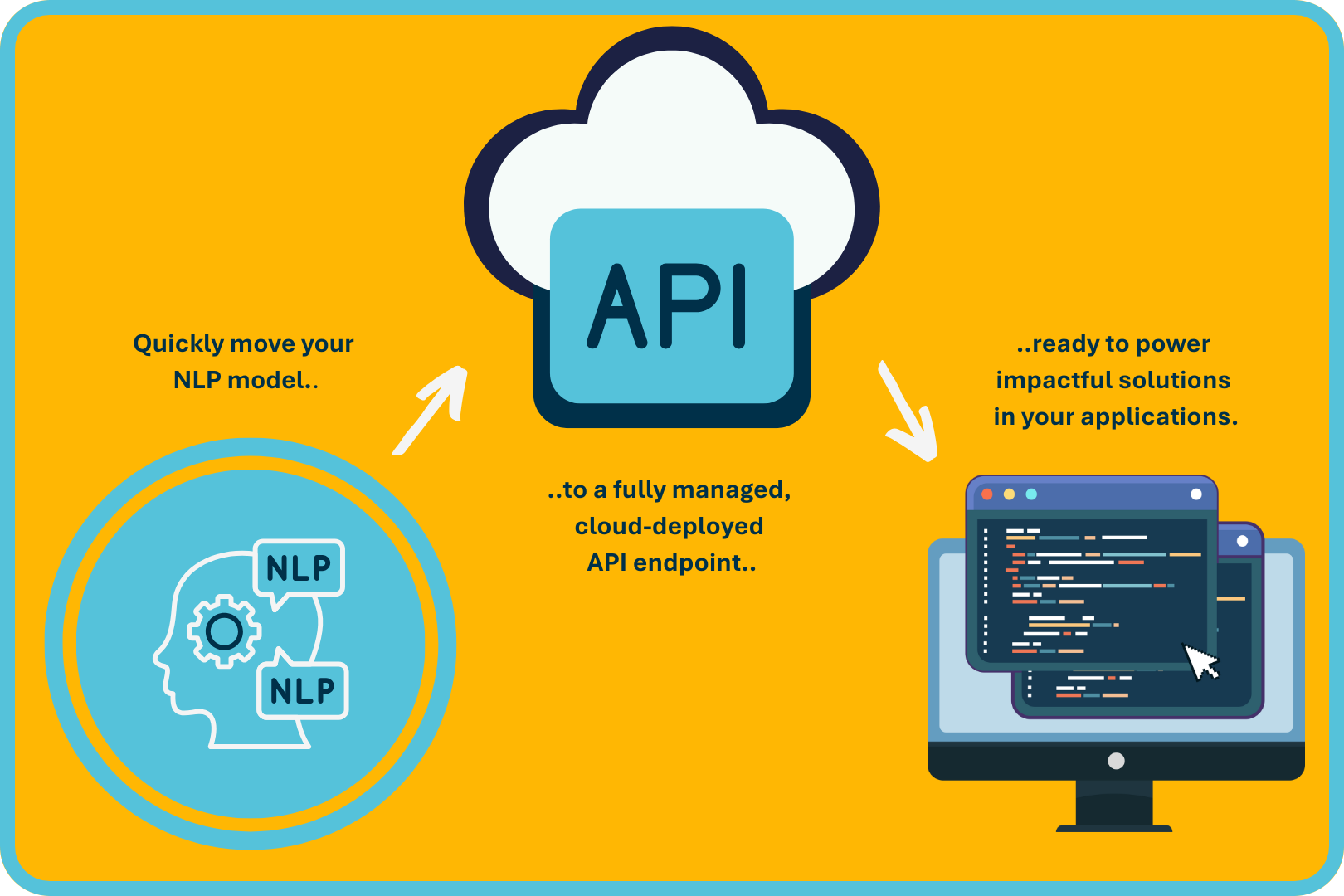
The primary benefit of deploying models behind API endpoints, rather than embedding them directly within applications, is decoupling. Specifically, deploying behind an API endpoint offers several key advantages:
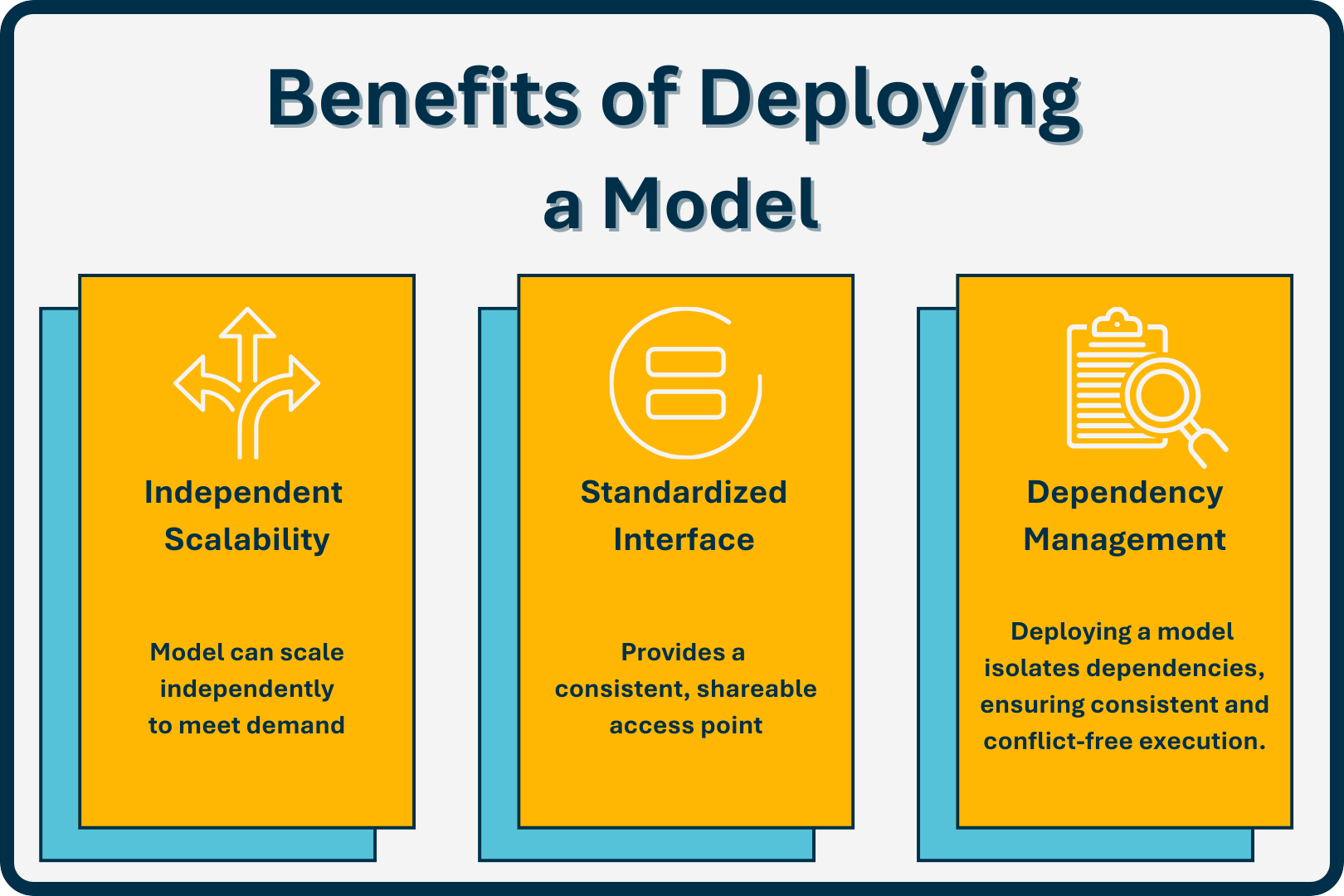
- Independent Scalability: The model serving layer can scale independently, handling increased usage or traffic spikes without affecting the application’s performance.
- Standardized Interface: An API provides a clear, consistent, and easily shareable interface, simplifying integration across diverse systems within an organization
- Simplified Dependency Management: Rather than managing individual runtime environments and dependencies across multiple applications, teams can interact with the model through a centralized, standardized service.
Studies have shown, however, that only a fraction of trained ML models ever reach production environments, highlighting the difficulty and complexity involved1.
The Deployment Bottleneck
As mentioned, deploying even seemingly simple NLP models into a production environment is notoriously complex and introduces a distinct set of challenges that align more closely with software engineering and operations (DevOps/MLOps) than data science. Model deployment shares the same concerns as deploying any software service.
Teams, especially those without dedicated MLOps or DevOps specialists, often face significant technical hurdles, these include:
- Infrastructure Setup: Deploying models typically requires provisioning cloud infrastructure (compute instances, API gateways, storage buckets). For engineers unfamiliar with Infrastructure as Code (IaC) or cloud platforms, this might involve manual configuration, increasing risks of misconfigurations, insecurity, and inconsistency. Setting up access control, secrets management, and networking can also be overwhelming.
- Dependency and Environment Management: NLP models rely on complex stacks of libraries (e.g., spaCy, numpy, transformers) with specific versions. Mismatches between development and production environments can cause silent failures or incorrect results. Dependency drift requires careful management, often using Docker containerization or virtual environments with pinned versions.
- Reproducibility: Manual deployments are hard to reproduce or audit. Without declarative configurations (IaC frameworks like AWS CDK or Terraform), tracking the production state is difficult, making rollbacks or handoffs fragile.
- Monitoring and Reliability: A deployed model is a live service often requiring uptime and observability. Without monitoring (health checks, tracing, logging, metrics), teams may be unaware of failures, performance degradation, or data drift.
- Security and Access Control: Exposing models via APIs creates attack surfaces. Access control (API keys, rate limits, authentication) helps prevent unauthorized use or data exposure.
- API Development: Building and maintaining the API interface itself requires software engineering effort.
- Scalability and Performance: Ensuring the service can handle the required load and meet latency requirements.

Many deployment workflows remain fragile and sensitive to inconsistencies between development and production. This is especially problematic in teams without dedicated expertise, where deployment becomes a bottleneck.
Roles and Responsibilities
Successfully navigating the ML lifecycle typically involves distinct roles:
- Data Scientist: Focuses on understanding data, selecting/developing algorithms, training models, and evaluating their performance. Their primary output is often a trained model artifact.
- ML Engineer / DevOps / Platform Engineer: Focuses on the operational aspects – taking the trained model artifact and building a robust, scalable, and reliable infrastructure to serve in production. They are responsible for packaging, managing deployment pipelines (CI/CD), automating infrastructure, monitoring, and scaling.
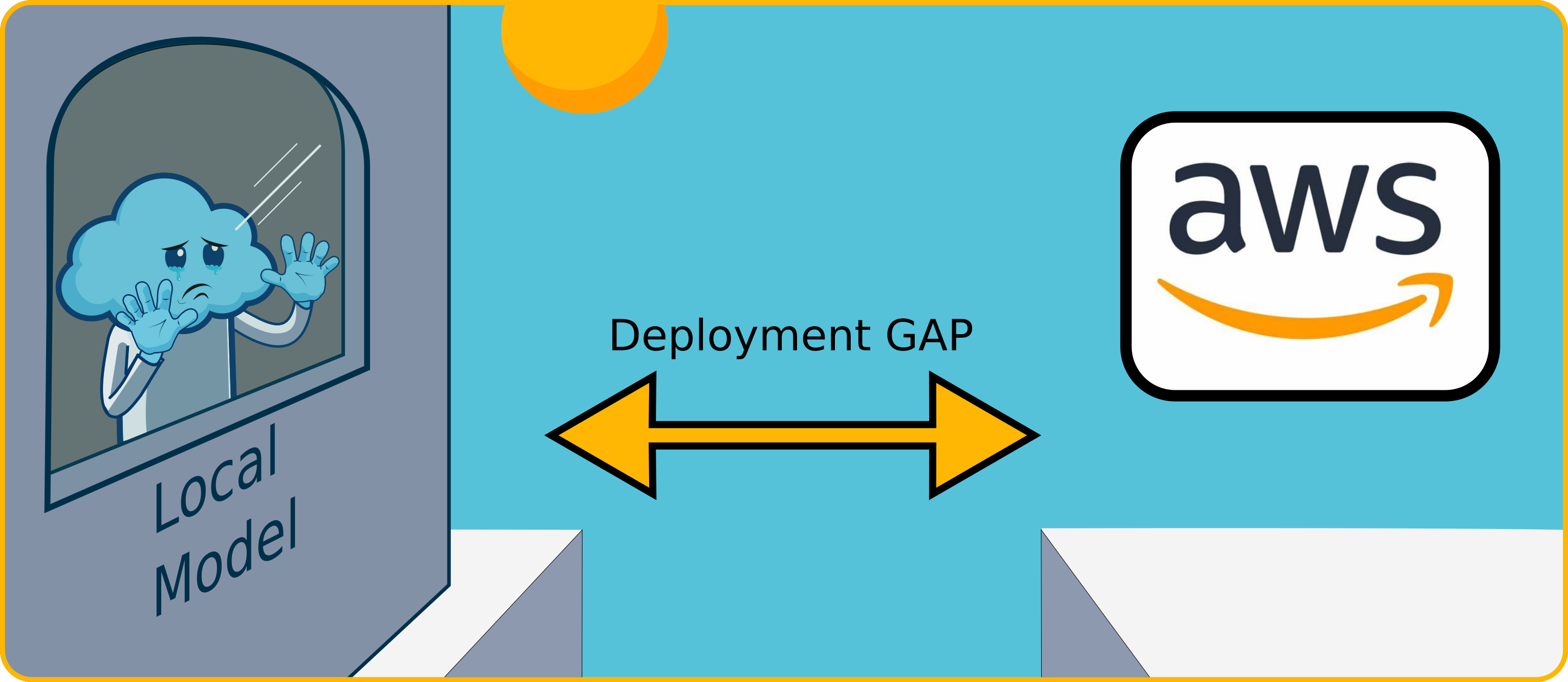
The challenge arises in organizations, particularly smaller teams or those new to ML, where the specialized ML Engineer role may not exist. In such cases, the deployment responsibility often falls to:
- Data Scientists: Who may lack the necessary software engineering, cloud infrastructure, or DevOps expertise and time.
- Generalist Software Engineers: Who may lack specific MLOps knowledge and tooling experience.
This "deployment gap" means that valuable, trained models often remain stuck, relegated to local machines and becoming part of the "model graveyard" instead of delivering value.
Deployment Strategies
Understanding the deployment strategy is essential when designing a solution, as different approaches have significant implications for infrastructure, latency, and operational complexity. NLP model deployments generally fall into one of two categories.
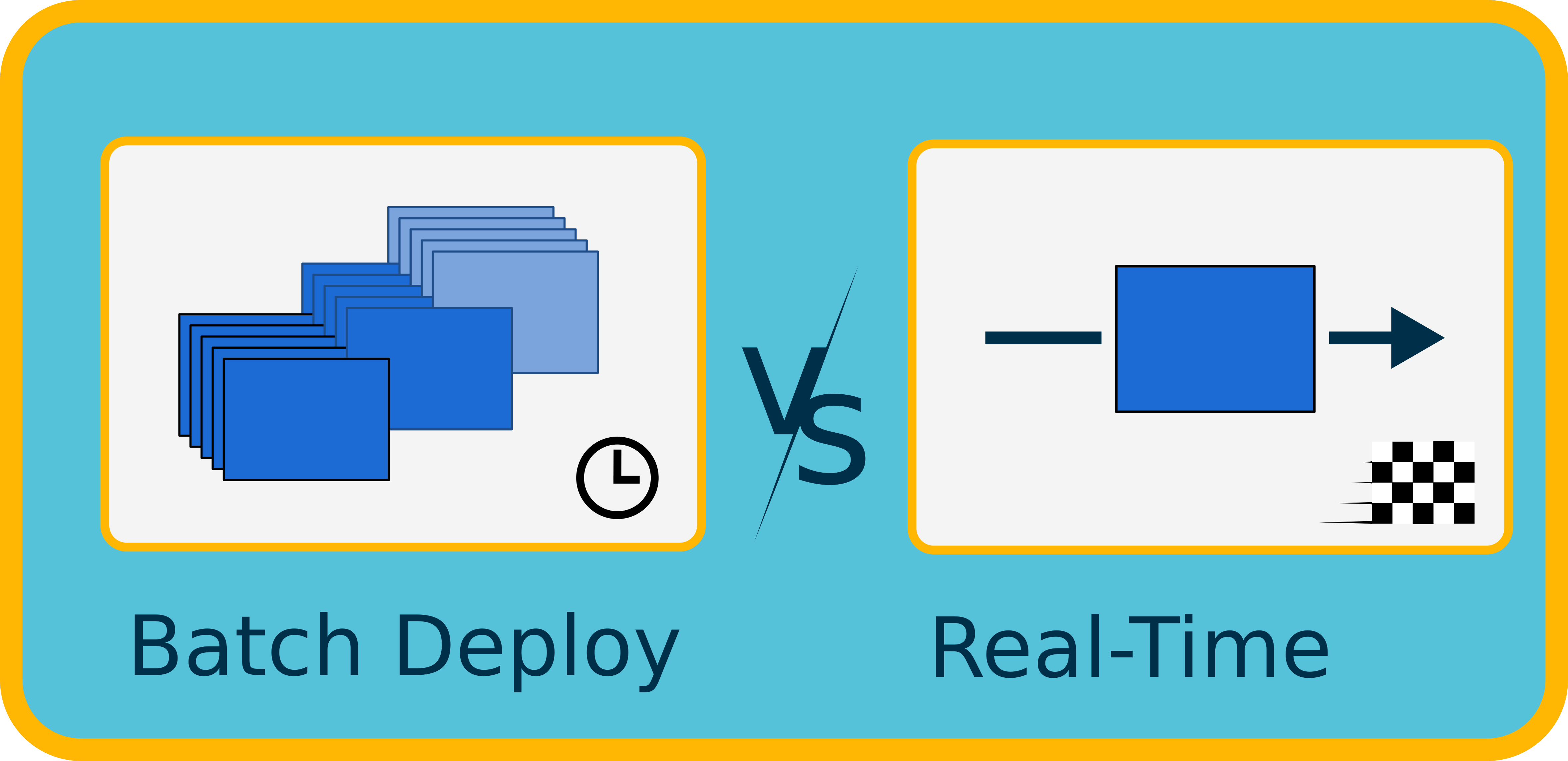
Real-Time Deployment
Real-time deployment exposes models through an always-available API endpoint that returns predictions immediately in response to input. This is essential when user experience depends on rapid model inference.
- Use Cases: Chatbots, live sentiment scoring, email routing, and interactive applications.
- Deployment Characteristics:
- Requires low-latency inference
- Needs to handle concurrent requests
- Typically integrated directly into user-facing systems
- Engineering Considerations:
- Cold starts and performance tuning often must be addressed
- Robust monitoring and alerting is frequently required
- Typically paired with caching or queuing systems to handle bursts in traffic
While real-time deployments unlock broader use cases, they introduce additional complexity. High-throughput use cases may require autoscaling container orchestration platforms such as ECS or Kubernetes, architectures that are more difficult for small teams to manage.
Batch Deployment
Batch deployment refers to running models on a fixed schedule or over larger datasets at once, typically as part of an offline processing pipeline.
- Use Cases: Processing historical data, extracting insights from a corpus of documents, sentiment analysis on daily customer reviews, etc.
- Deployment Characteristics:
- Invocation frequency is low
- Longer execution durations are tolerated
- Outputs are often not returned in real-time, but rather are stored in a database or file system
- Engineering Considerations:
- Lower focus on latency
- Simpler to break up tasks to run at the same time
For Nimbus, batch processing aligns closely with the needs of our target users—small data science teams or individual developers building internal tools to analyze unstructured data such as customer feedback, product reviews, or team recommendations. These models are not invoked constantly or in high-throughput production environments, but rather are executed intermittently as part of internal workflows. Supporting batch-style deployments allows Nimbus to optimize for low cost, low complexity, and quick deployment turnaround.
Existing Deployment Solutions
Given the aforementioned challenges and the choice between batch and real-time strategies, teams usually rely on external deployment solutions, each with its own strengths and drawbacks. Existing options generally fall into three categories:
Managed Platforms

Managed platforms like AWS SageMaker simplify deployment significantly by providing pre-configured infrastructure and built-in scalability. They handle many underlying complexities and offer convenient tools for monitoring and managing models. These services, however, are often expensive, particularly for smaller or budget-conscious teams, as costs can quickly accumulate, especially with continuous or idle usage. Additionally, managed services may result in vendor lock-in, restricting flexibility and control over infrastructure and data privacy. As a result, these platforms, while powerful and user-friendly, often don’t align well with smaller teams’ needs or budgets.
Open-Source Model-Serving Frameworks

Open-source model-serving frameworks like BentoML offer greater flexibility and customizability than managed platforms, enabling teams to tailor deployments closely to their specific requirements. This flexibility, however, often comes at a steep cost in terms of configuration complexity and required expertise. These frameworks typically demand extensive initial configuration and ongoing management, making them challenging for smaller teams that lack dedicated MLOps or DevOps personnel. While these tools can support diverse model types and deployment patterns, the corresponding operational overhead and configuration frequently outweigh their benefits, especially for simpler, focused NLP deployments.
DIY Solutions

The 'do-it-yourself' approach, using tools like Flask/FastAPI and Docker, offers more control but comes at a high cost in complexity and effort. Teams choosing this path must manually build and maintain the entire infrastructure stack needed to serve their model, which is a significant and often underestimated task. This involves constructing everything from the ground up, a process that is not only complex and time-consuming but also difficult to standardize; this can lead to inconsistencies and errors.
Current Deployment Gap
The complexities inherent in NLP model deployment, the associated skill gaps, and the tradeoffs accompanying existing solutions collectively create a clearly identified deployment gap. Small data science teams and individual researchers often find themselves forced to choose between expensive managed services, overly complex open-source tools, or labor-and-expertise-intensive DIY setups.
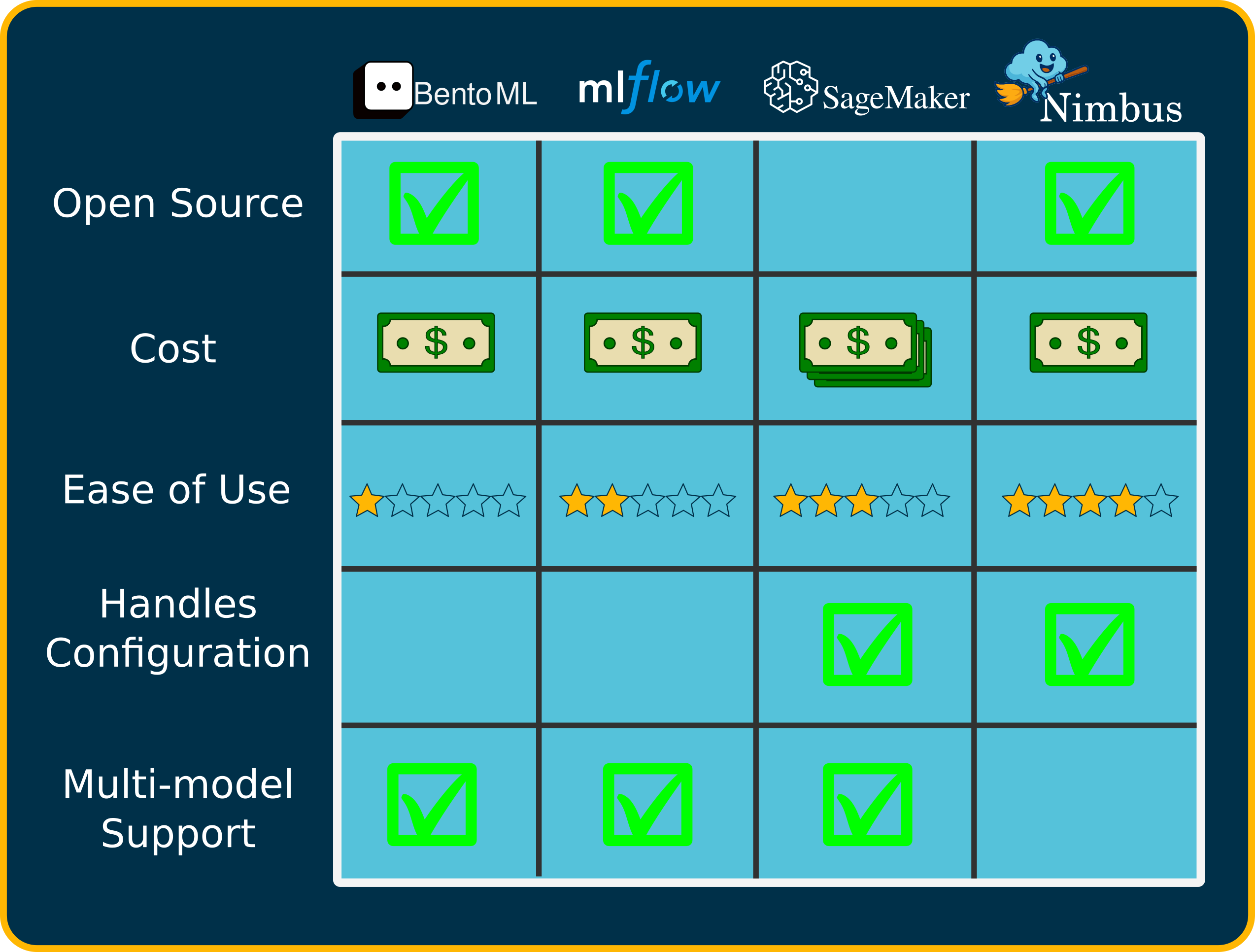
This highlights a need for a simpler, more accessible way to deploy lightweight NLP models. Many teams require solutions that abstract away the intricate details of cloud infrastructure, containerization, API development, and ongoing operations. The ideal solution, particularly for smaller teams and batch-oriented or intermittent use cases, would automate the MLOps tasks, enabling data scientists to focus on model optimization and developers to focus on creatively integrating those models into their applications.
This creates the perfect context for Nimbus: a tool designed specifically to fill this deployment gap by providing an automated, simple, and cost-effective pathway to get lightweight NLP models (currently SpaCy models for batch processing) into production quickly and reliably, without requiring deep MLOps expertise.
Footnotes
-
https://www.gartner.com/en/newsroom/press-releases/2020-10-19-gartner-identifies-the-top-strategic-technology-trends-for-2021; https://www.forbes.com/councils/forbestechcouncil/2023/04/10/why-most-machine-learning-applications-fail-to-deploy/; https://d2iq.com/blog/why-87-of-ai-ml-projects-never-make-it-into-production-and-how-to-fix-it ↩