Background
The Core Challenge: From Trained Model to Real-World Value
Machine Learning (ML) enables systems to learn patterns from data to perform tasks like prediction or classification, while Natural Language Processing (NLP) is a specific field of ML focused on understanding and processing human language. Businesses use these technologies to gain valuable insights from data. A trained model, however, often just a file on a data scientist's machine, provides no business value until it's operational. The critical step in operationalizing said model is deployment: transforming the model into a live, accessible service (typically an API endpoint) that applications can query.
This transition from a static model file to a dynamic, production-ready service is fundamentally a software engineering and operations (DevOps/MLOps) challenge, not just a data science one. It involves bridging the gap between the model itself and the complex ecosystem required to run it reliably and at scale. The typical Machine Learning lifecycle (Data Collection -> Training -> Deployment -> Monitoring -> Iteration) often hits a significant bottleneck at the deployment stage, preventing models from ever reaching end-users. It is important to keep this in mind while we set the stage by providing some background on NLP.
What is NLP?
Natural Language Processing (NLP) is a field at the intersection of computer science, artificial intelligence, and linguistics.1 Its primary goal is to enable computers to understand, interpret, and generate human language in meaningful ways. Modern NLP systems accomplish this by combining rule-based linguistic techniques with statistical machine learning and deep learning methods.
NLP is often divided into two broad categories:
Natural Language Understanding (NLU), which focuses on interpreting human-generated language
Natural Language Generation (NLG), which focuses on producing coherent, human-like responses
This case study focuses primarily on deploying NLU models, specifically the models and systems that help machines comprehend text such as emails, articles, support tickets, and chat messages. Given that an estimated 80–90% of the world’s data is unstructured—and much of it text-based—there is a growing need for tools that can analyze language at scale.2
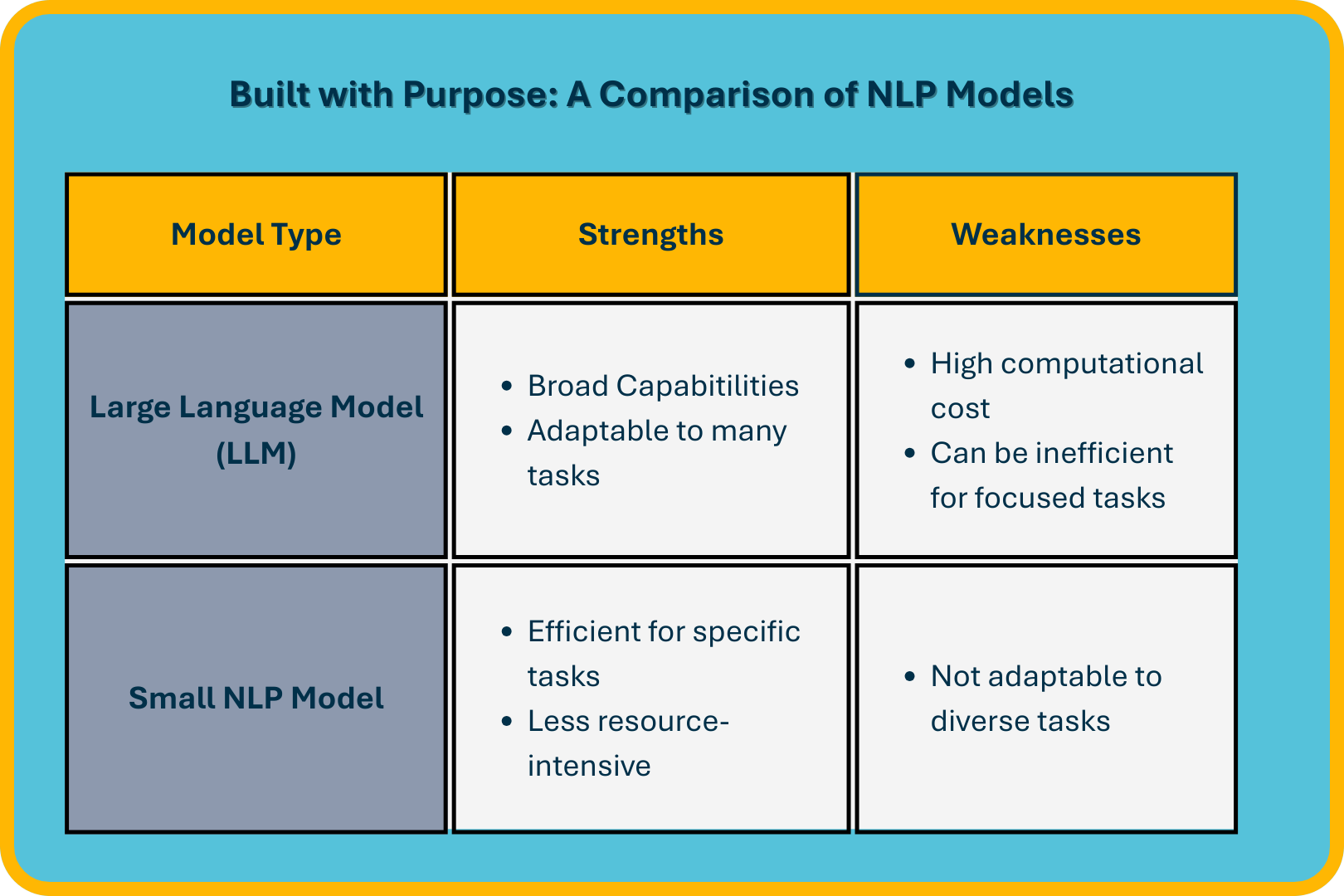
If you’ve ever interacted with models like OpenAI’s GPT-4 or Meta’s Llama 4, then you’ve already encountered NLP in action. These models represent the frontier of modern NLP, capable of tackling a wide array of general-purpose tasks; while powerful, they are not always the best fit for narrower, domain-specific problems. In these cases, smaller, more efficient NLP models can deliver faster, cheaper, and more focused performance.

What are Small NLP Models?
Despite the growing popularity and impressive capabilities of large-language models like GPT and Llama 4, these expansive architectures are often unnecessary and costly for many practical, focused NLP tasks. Their substantial computational demands, high costs, and complex infrastructure requirements limit their accessibility for smaller teams or budget-constrained projects.
Smaller NLP models provide targeted, cost-effective solutions. They excel in use cases such as sentiment analysis, entity recognition, and text classification by balancing computational efficiency with rapid inference speed and straightforward deployment.
An example of these model types would be spaCy3 models, which come from a production-grade NLP library built for efficient natural language processing. spaCy provides pre-trained pipelines for common tasks like those mentioned above, making it an ideal choice for lightweight applications.
Nimbus was built to deploy these smaller-scale NLP models like spaCy models, enabling developers and small teams to harness actionable NLP insights without requiring extensive resources or specialized expertise.
Practical Applications of Small NLP models:
As mentioned, small NLP models are particularly well suited for tackling narrowly-focused or specific tasks. Despite the narrow use cases for these models, the targeted insights they provide offer significant value in real world application. Below are several examples of the types of insights they provide:
Sentiment Analysis
The use of sentiment analysis to gauge public opinion or customer sentiment is widespread across various industries. Small NLP models that provide this functionality do so by classifying text (consisting of reviews, social media posts, or customer feedback) into sentiment categories – typically positive, neutral, or negative. Use cases include:
- E-commerce: Automatically analyzing product reviews to rapidly identify and address customer issues or dissatisfaction.
- Social Media Monitoring: Gaining a real-time gauge of brand perception by assessing user-generated content across various platforms.
- Customer Support: Parsing and prioritizing support tickets, improving response times and customer satisfaction.

Named Entity Recognition (NER)
Models that can conduct Named Entity Recognition detect and categorize entities in text. These entities can include names, dates, locations, or organizations. Compact NER models can be utilized to efficiently parse large volumes of textual data. Some example use cases of NER include:
- Contact information management: Identifying email addresses, phone numbers, or names from customer inquiries, enabling streamlined CRM integration and efficient customer outreach.
- Document Organization: Quickly extracting structured information like invoice numbers, transaction dates, or vendor names from financial or administrative documents, reducing manual data entry and administrative workload.
- Legal and Compliance: Automatically extracting essential details from standard legal documents, such as involved parties, dates and relevant clauses. This can significantly accelerate the review process while still ensuring accuracy.

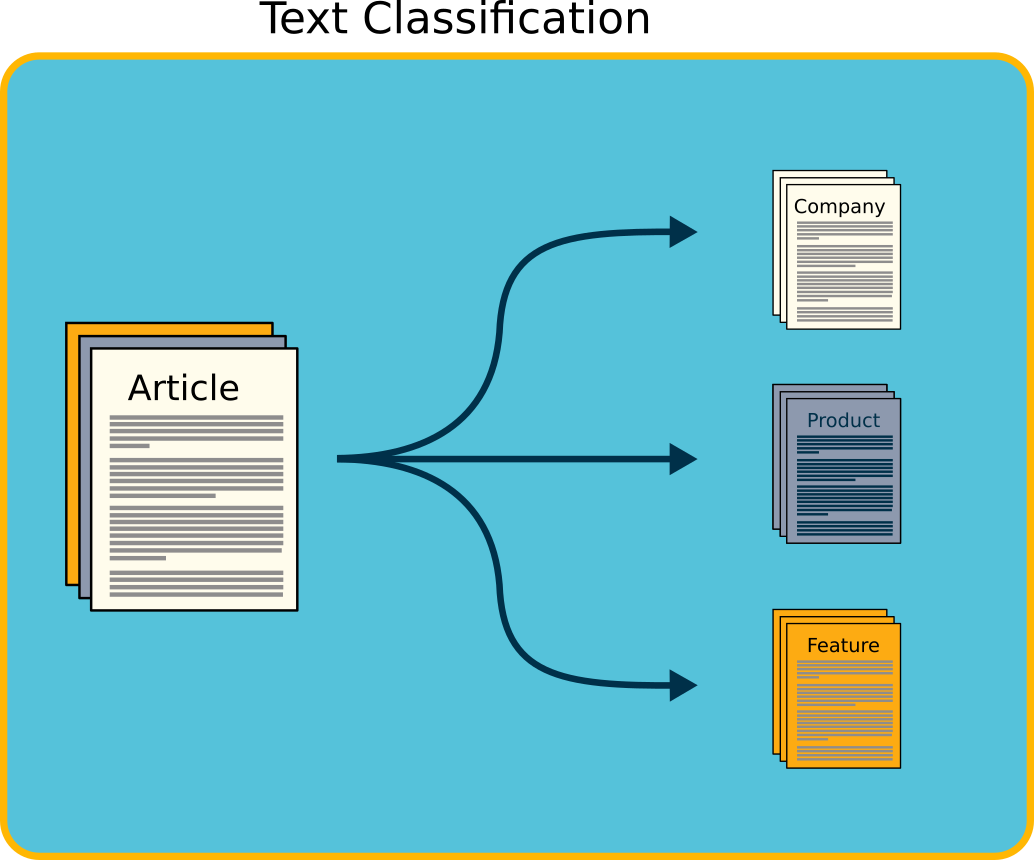
Text Classification
Text classification involves assigning predefined categories or tags to documents or text entries based on their content. Task-specific NLP models are effective in automating this process, allowing smaller organizations to manage large volumes of textual information efficiently. Common applications include:
- Customer Support Routing: Classifying customer support inquiries or tickets into their respective categories, automatically routing them to the correct support department or individual. This can greatly enhance response/resolution efficiency.
- Content Management: Automatically assigning tags or categories to articles, blog posts, or internal documentation, facilitating easier retrieval and improved organization.
- Email filtering: Rapidly categorizing incoming emails based on type or urgency. This can significantly reduce inbox clutter, ensure timely responses, and optimize overall communication management.
The above examples demonstrate how compact, task-specific NLP models, when effectively deployed, enable small organizations to achieve significant efficiency gains and glean practical insights without requiring extensive resources or specialized infrastructure.